Constraints in Odoo serve as rules defined on a record to preemptively thwart the storage of inaccurate data before the record is saved. Odoo consistently upholds data integrity by rigorously enforcing these validation processes, ensuring the preservation of complete and accurate data.
In Odoo 17 data constraints are established through Python code and model constraints. These constraints primarily serve the purpose of validating record data before it is persisted in the database. Now, let's delve into Python and SQL constraints in Odoo 17.
1.SQL Constraints
Model-specific SQL constraints are declared in Odoo by utilizing the class attribute _sql_constraints. These constraints are associated with the PostgreSQL database system. The attribute _sql_constraints is configured as a list of triplets of strings, adhering to the syntax outlined below. It is defined in the field declarations section.
_sql_constraints = [name, sql_def,message]
Name: The identifier for the constraint
Sql_def: PostgreSQL syntax defining the constraint
Message: Error message presented to users in case the constraint or its conditions are not met.
class Student(models.Model):
_name = 'student.student'
_sql_constraints = [('roll_number_unique', 'unique(roll_number)', "The roll number is unique for each student.!")]
The frequently employed SQL constraint, UNIQUE, prohibits data duplication for a specified field. This constraint is associated with a field name, preventing duplicate entries for that particular field.
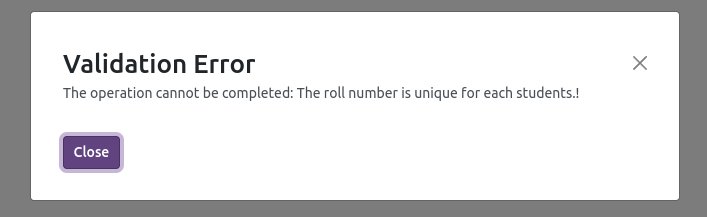
The provided _sql_constraints attribute in your code snippet suggests that a constraint named 'roll_number_unique' is defined. This constraint ensures the uniqueness of the 'roll_number' field in your model. If a duplicate 'roll_number' is detected during database operations, it will trigger an error: "The roll number is unique for each student!".
When the unique constraint detects duplicity of data, the error message is presented in the following manner:
The CHECK constraint within _sql_constraints examines SQL expressions on the data to ensure adherence to specified conditions. For instance,
_sql_constraints = [
('roll_number_unique', 'unique(roll_number)', "The roll number is unique for each student!"),
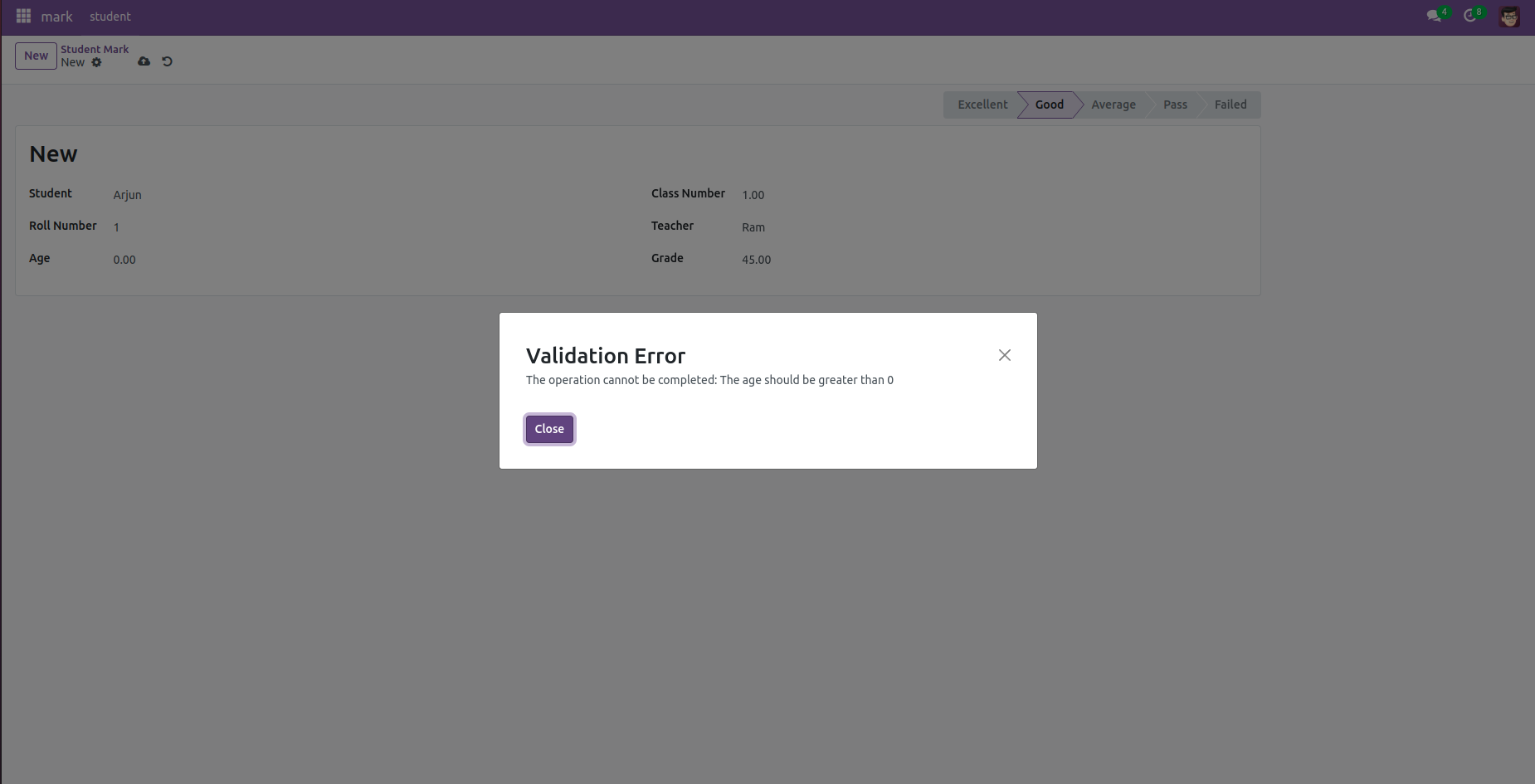
('positive_age', 'CHECK(age > 0)', 'The age should be greater than 0.')]
This example illustrates the application of CHECK constraints within _sql_constraints. Specifically, the constraints, named 'positive_age,' verify whether the age is greater than 0. If the age fails to meet this criterion, it triggers an error message.
In instances where more sophisticated checks are required for maintaining data consistency, Python constraints become essential. These constraints entail a method adorned with constraints, designed to be invoked on a set of records to ensure thorough validation.
Python constraints employ custom code to validate data records. This validation is executed through a function adorned with the ‘@api.constrains’ decorator.
To display an exception, it is necessary to import either 'ValidationError' or 'UserError' in the code.
@api.constrains('age')
def _check_something(self):
for record in self:
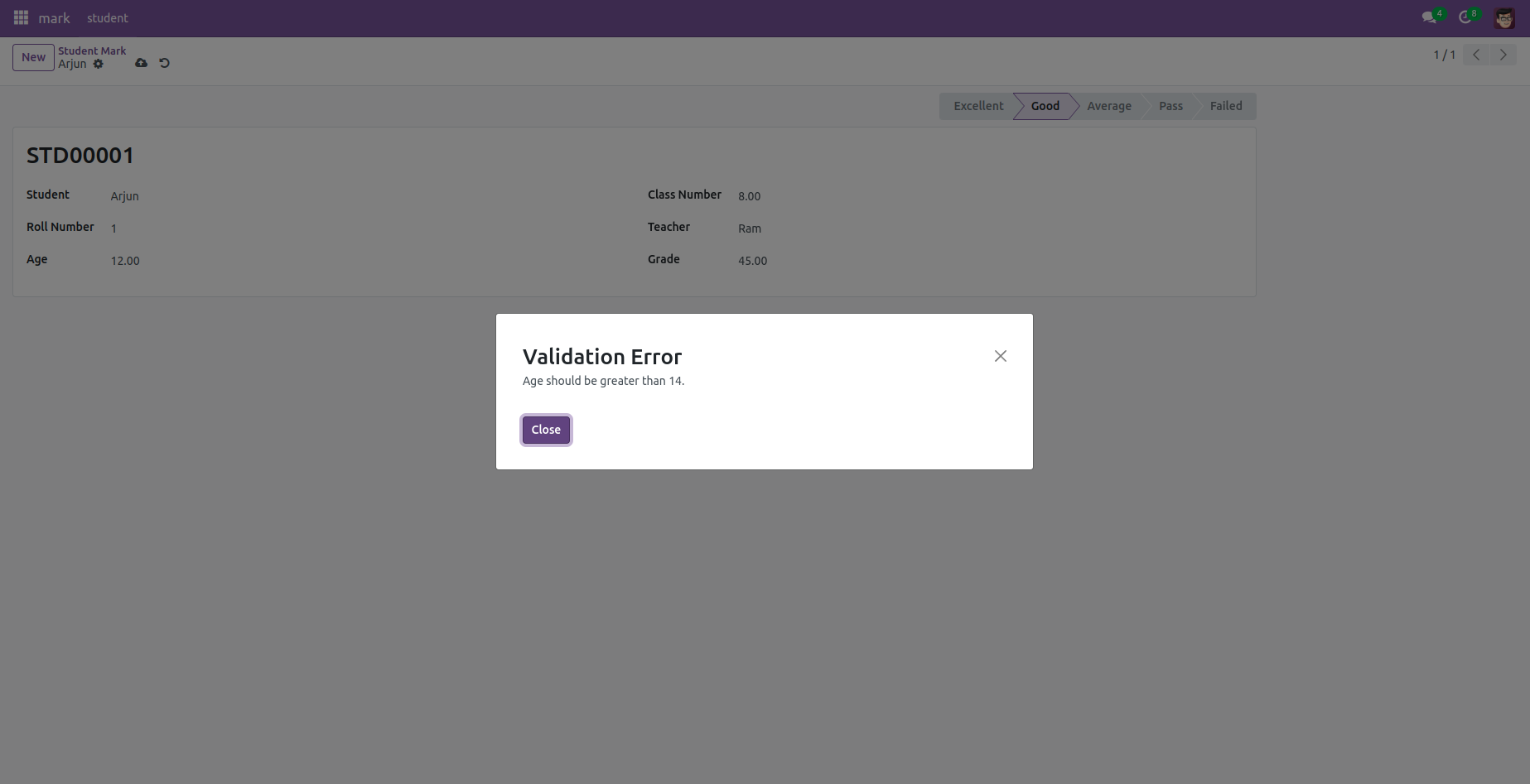
if record. age < 14:
raise ValidationError(_('Age should be greater than 14.'))
In this illustrative example, constraints are applied to the 'age' field within a model to verify whether the age exceeds 14. If the validation fails, indicating that the age surpasses 14, a Validation error message "Age is greater than" is displayed; otherwise, no response is returned.
The @api.constrains decorator exclusively supports simple fields, such as partner_id, and does not accommodate other related fields, like partner_id.phone, as they are ignored.
@api.constrains has additional limitations, specifically, it will only be activated if the field referenced within the constraints is included in the 'create' or 'write' functions. This is due to the fact that if the fields are not present in the view, the associated Python functions will not be triggered.
While both Python constraints and SQL constraints serve to ensure data consistency, SQL constraints are regarded as more potent and efficient in comparison. Despite the capability of each to fulfill specific requirements, both contribute to maintaining data consistency.